# 2025-capstone
작성: AI / 수정: nkey
라즈베리파이 k3s 클러스터(마스터/워커) + 모니터링/알람 + 자동 조치(승인/검증 포함) 데모를 위한 조직 레포입니다.
(Tailscale VPN 환경에서 k3s, Oracle 서버(n8n/WMS/DB), GPU 서버(Ollama/llama3)를 연동)
## What’s Inside
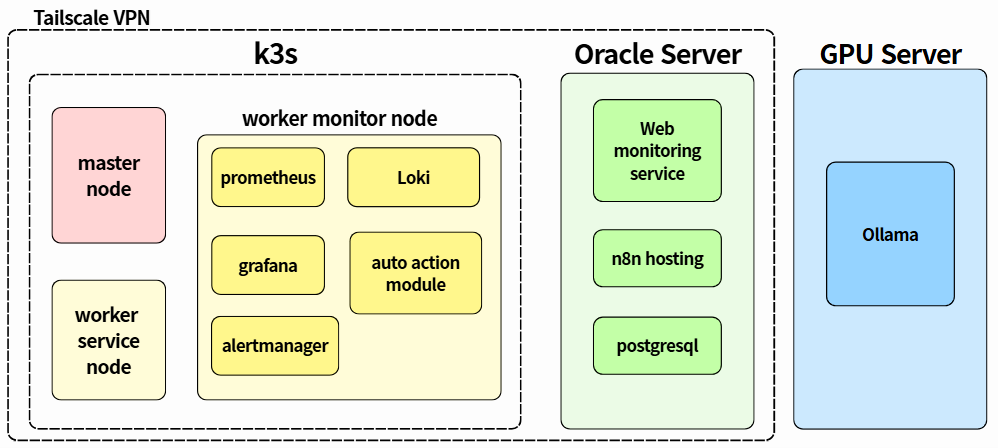
- **k3s 클러스터**
- **master node**: 클러스터 관리 + 매니페스트 적용(데모/모니터링 K8s 리소스)
- **worker service node**: 서비스 실행 노드(디스크 채우기 데모 Pod exec)
- **worker monitor node**: 모니터링 스택(Prometheus/Alertmanager/Loki/Grafana + auto action module)
- **Oracle Server**
- Web Monitoring Service(WMS)
- n8n hosting
- PostgreSQL
- **GPU Server**
- Ollama + llama3 (솔루션 생성/검증)
## Docs
- 각 레포지토리별 자세한 실행/구성은 해당 레포의 README를 참고하세요.
- `rpi-master-node/README.md`
- `rpi-worker-monitor-node/README.md`
- `rpi-worker-service-node/README.md`
- `oracle-server/README.md`
## Architecture
### High-level (요약)
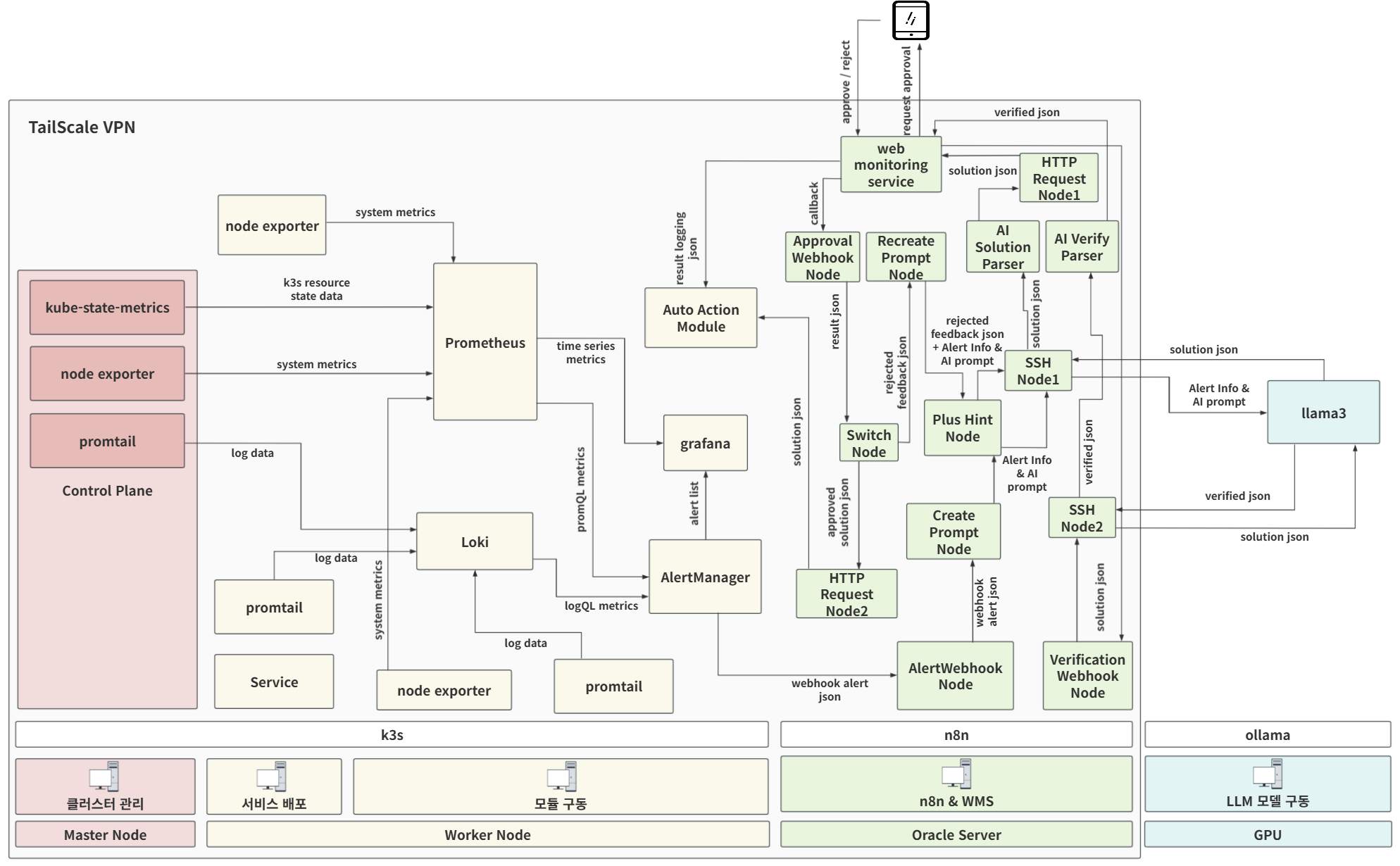
### End-to-end Flow (상세)
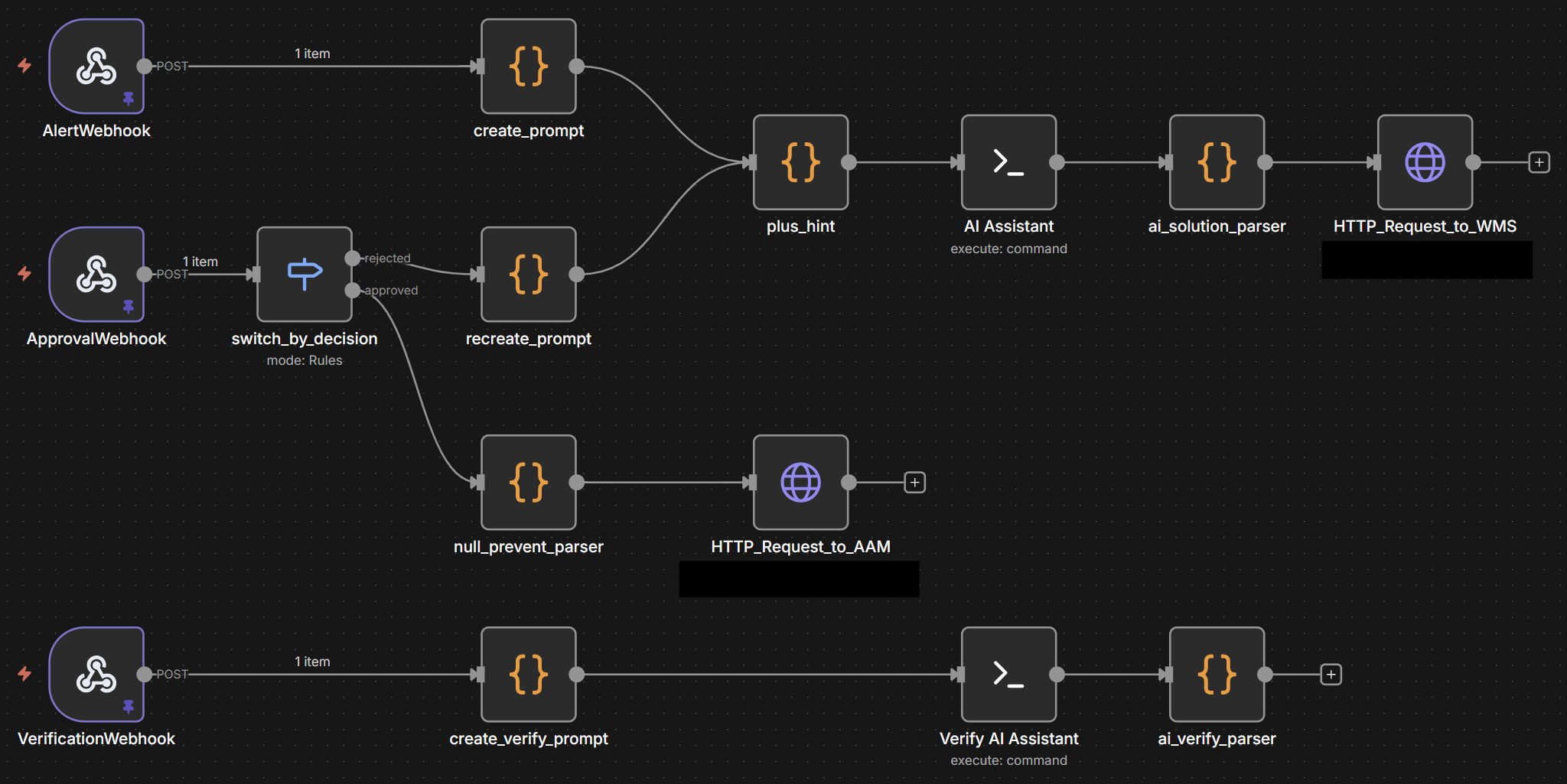
### n8n Flow
## Repositories
- `rpi-master-node`
- k3s 매니페스트(예: `k3s-manifests/disk-fill-demo.yaml`, `k3s-manifests/aam-deploy.yaml`)
- K8s 기반 모니터링 스택 매니페스트(`k3s-monitoring/*`)
- kube-state-metrics 매니페스트(`kube-state-metrics/*`)
- `rpi-worker-monitor-node`
- `monitoring/docker-compose.yml` 기반 Prometheus/Alertmanager/Loki/Grafana 구동(워커 모니터 노드)
- `rpi-worker-service-node`
- 서비스 워커 노드(레포가 비어있을 수 있음)
- **중요:** 디스크 채우기 데모는 **master 노드 레포의 `disk-fill-demo.yaml`을 배포**한 뒤, **service 노드에서 Pod에 exec**하여 스크립트를 실행합니다.
- `oracle-server`
- n8n으로 자동화 워크플로우 구현
- PHP 기반 Laravel 프레임워크를 활용하여 개발한 웹 모니터링 서비스(WMS)
## Quickstart (Demo: DiskAlmostFull 알람 → 자동 조치 → 검증)
### 1) (Master) 디스크 채우기 데모 배포
```bash
# master 노드에서
git clone https://nkeystudy.site/gitea/2025-capstone/rpi-master-node.git
cd rpi-master-node
kubectl apply -f k3s-manifests/disk-fill-demo.yaml
kubectl get pod -n alert-service -l app=disk-fill-demo
kubectl get svc -n alert-service
```
### 2) (Master -> Service Worker) Pod exec로 디스크 채우기 / 정리 실행
> 아래 명령은 **Master 노드**에서 실행되는 시나리오를 기준으로 합니다.
```bash
# Pod 이름 확인
POD=$(sudo kubectl get pod -n alert-service -l app=disk-fill-demo -o jsonpath='{.items[0].metadata.name}')
# 절대경로로 실행
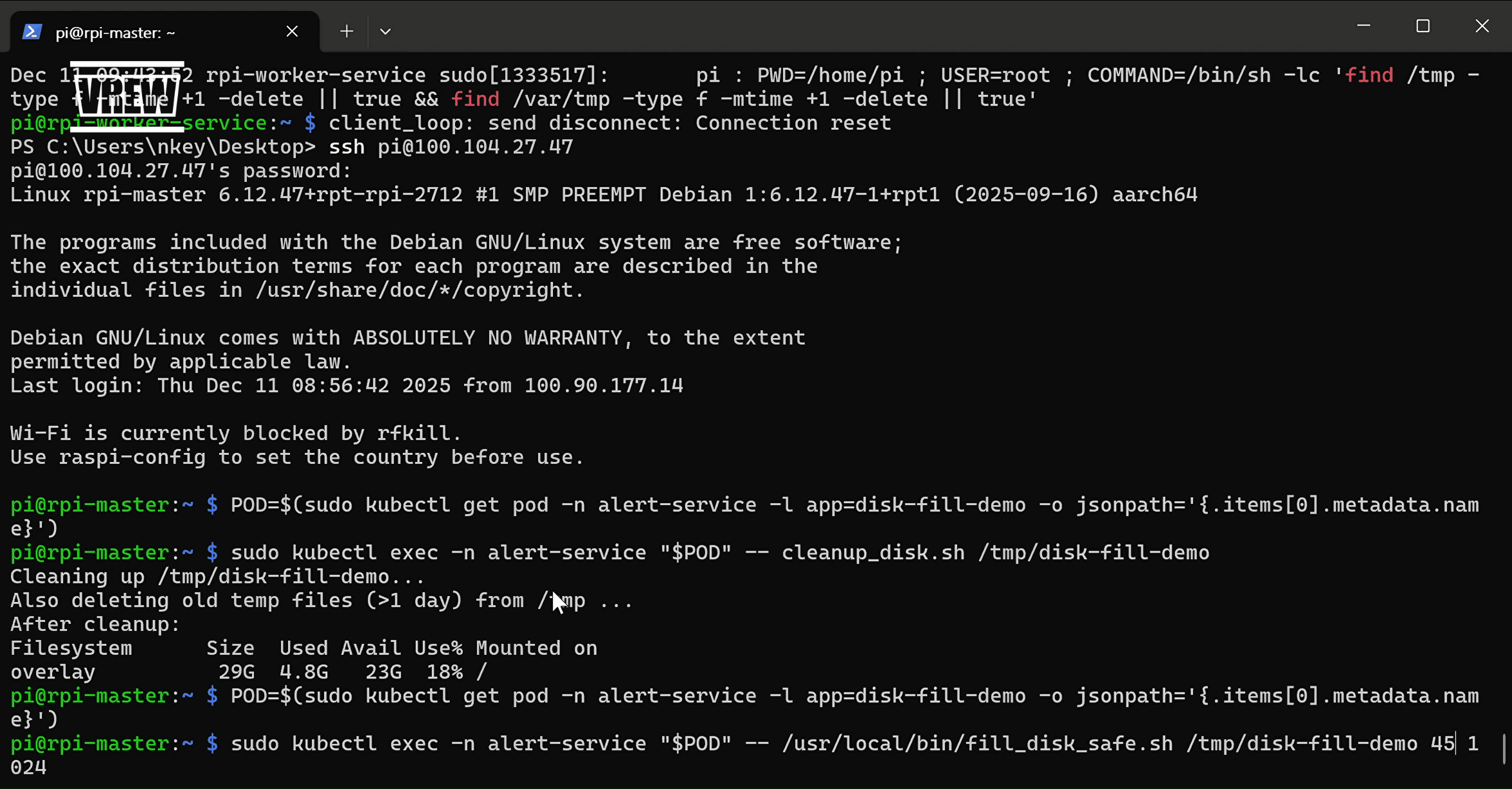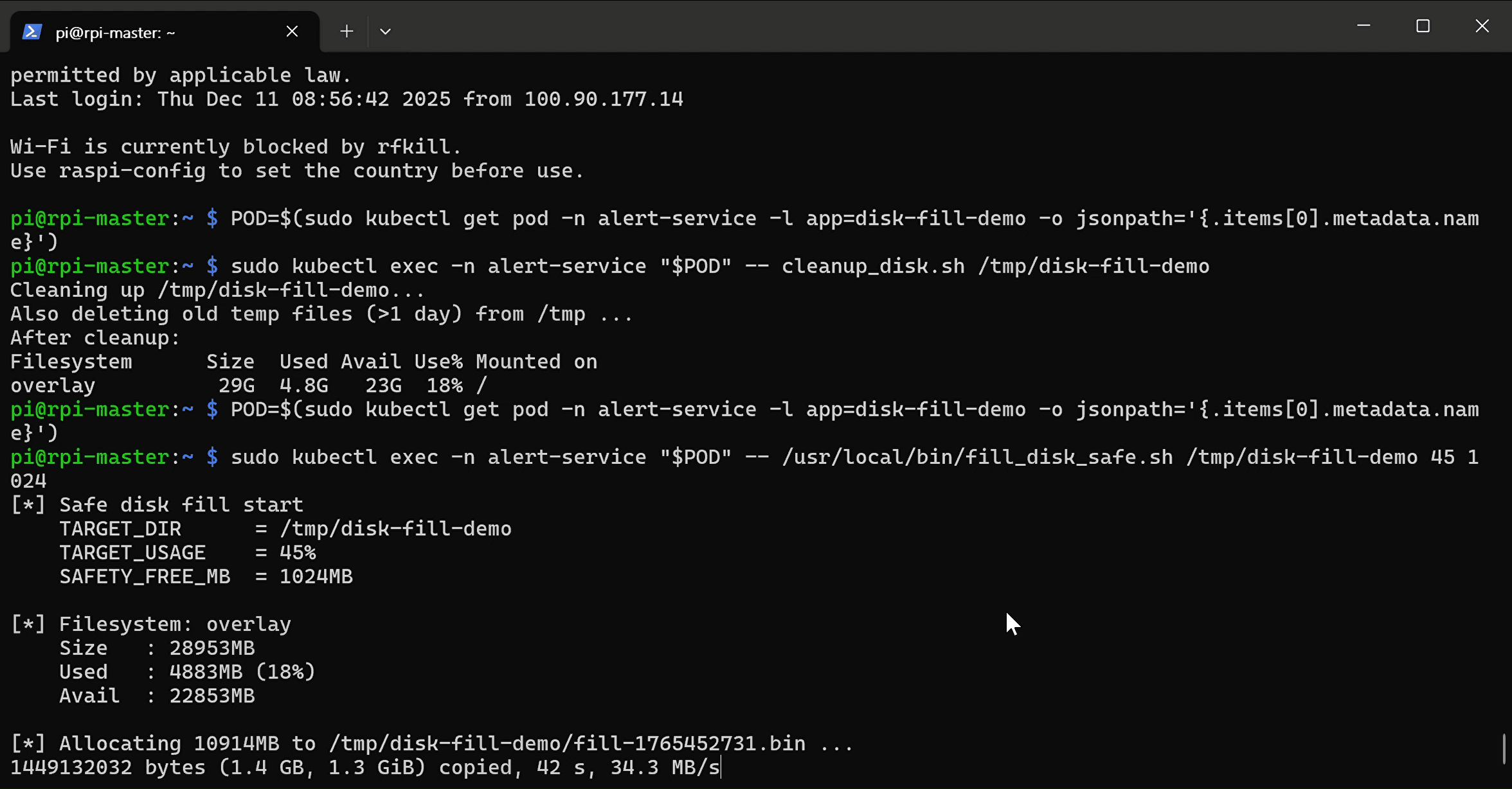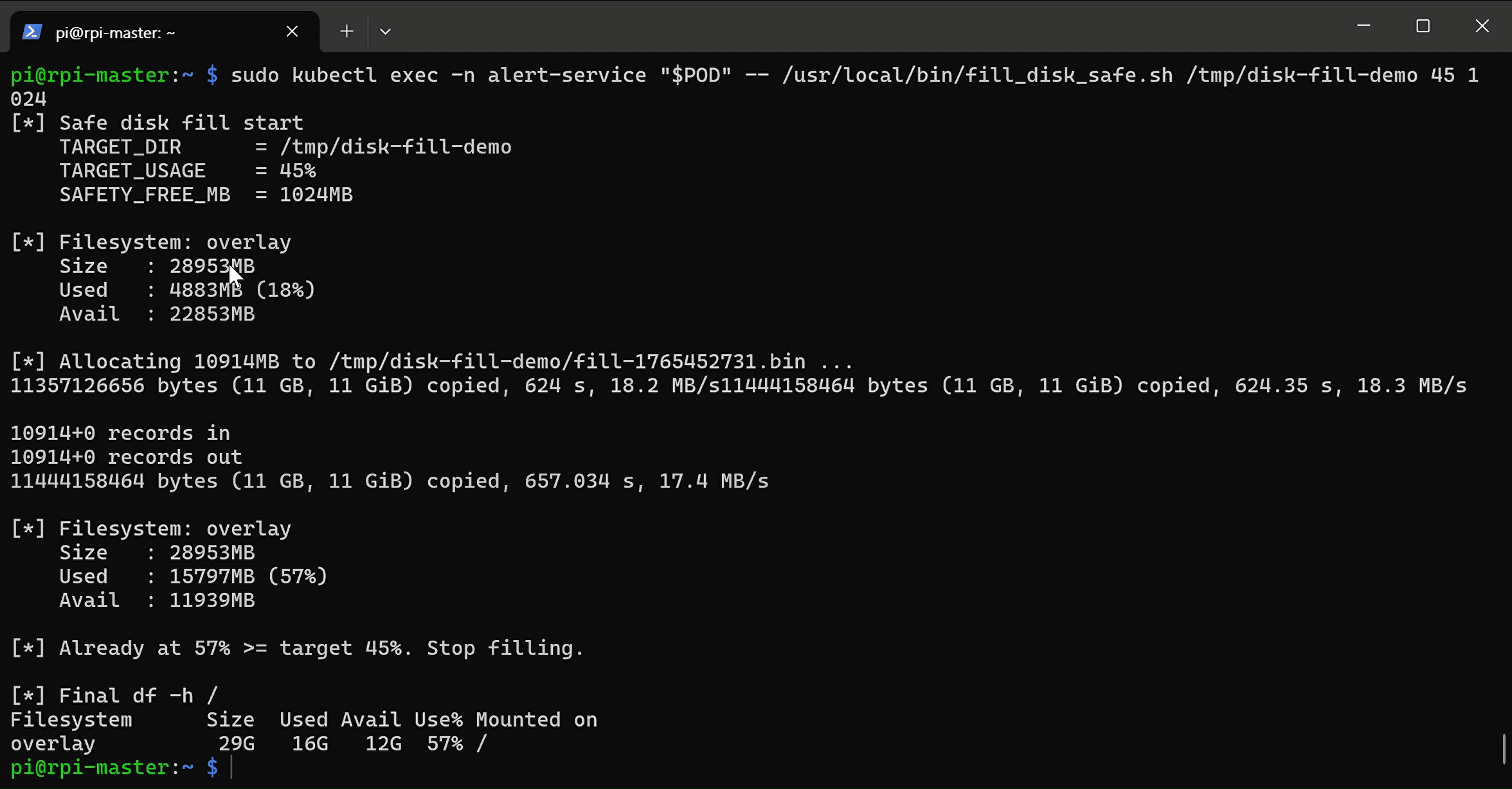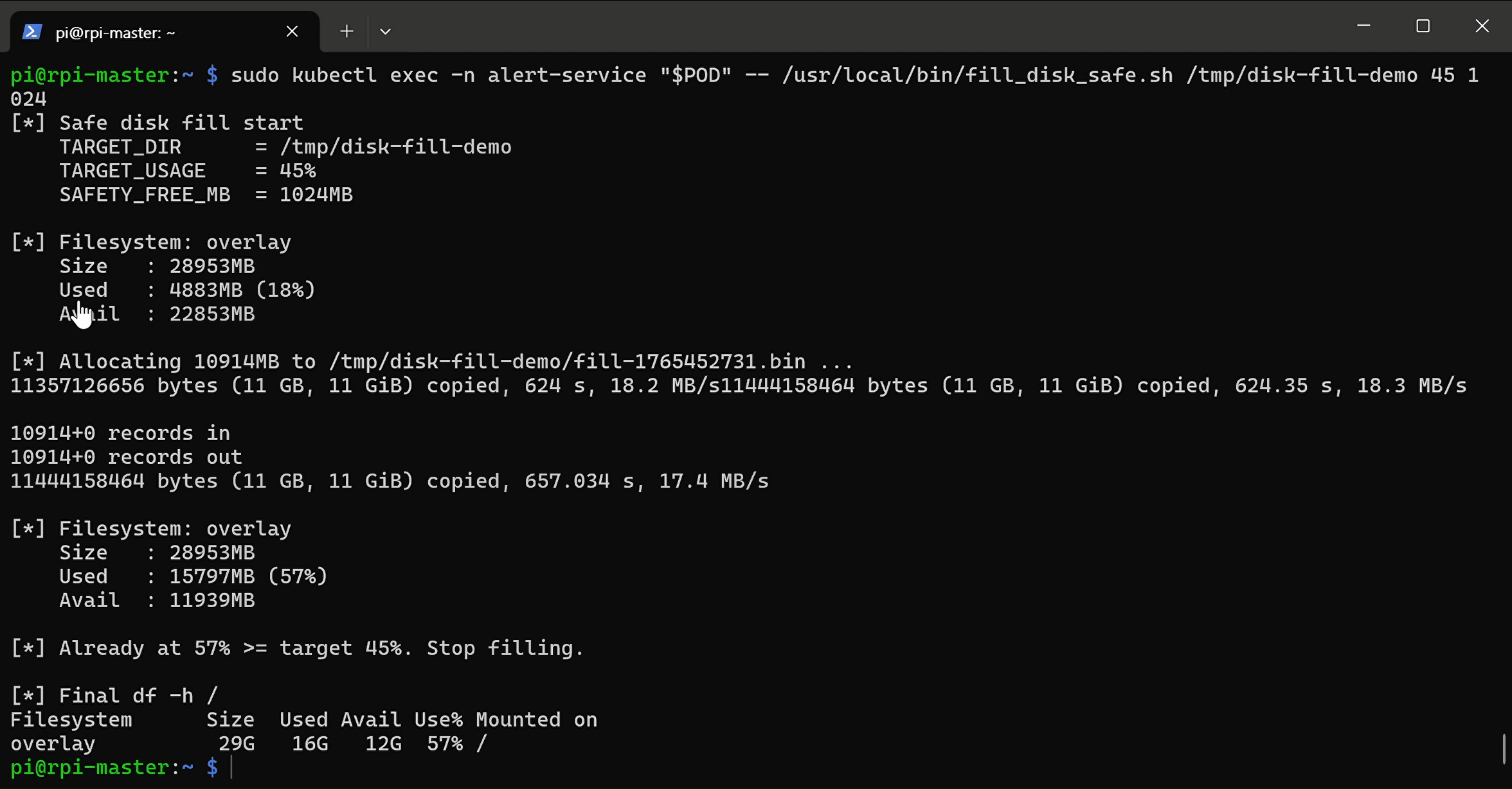
sudo kubectl exec -n alert-service "$POD" -- /usr/local/bin/fill_disk_safe.sh /tmp/disk-fill-demo 90 1024
# 상대경로로 실행
sudo kubectl exec -n alert-service "$POD" -- fill_disk_safe.sh /tmp/disk-fill-demo 90 1024
# 수동 해결(cleanup 셸 스크립트 실행)
sudo kubectl exec -n alert-service "$POD" -- cleanup_disk.sh /tmp/disk-fill-demo
```
### 3) (UI) 웹 페이지에서 확인
- disk full alert prometheus로 확인(2_check_disk_full_demo_result_in_prometheus)

- 해결책 생성 과정 워크플로우 동작 확인(3_check_make_solution_n8n_workflow)
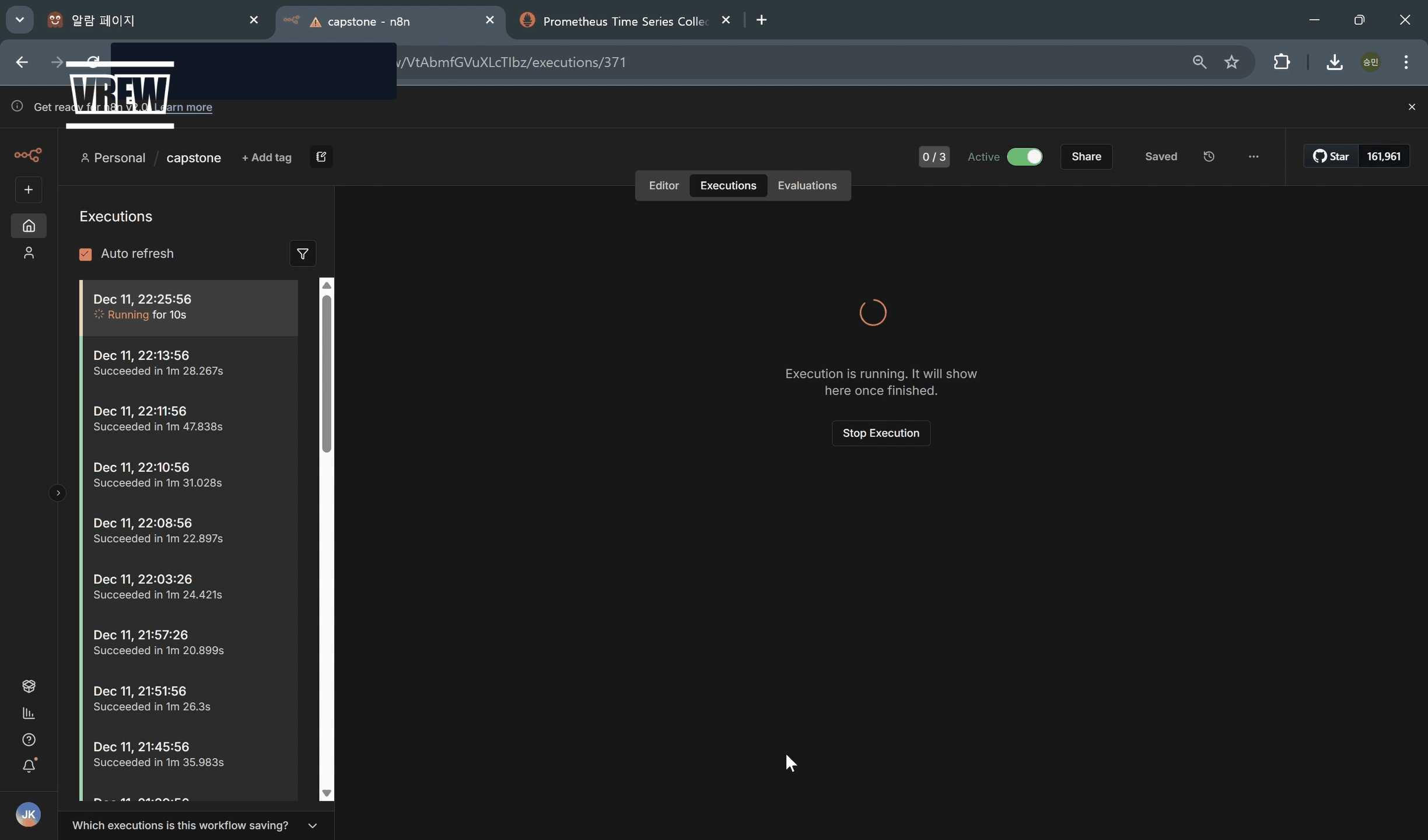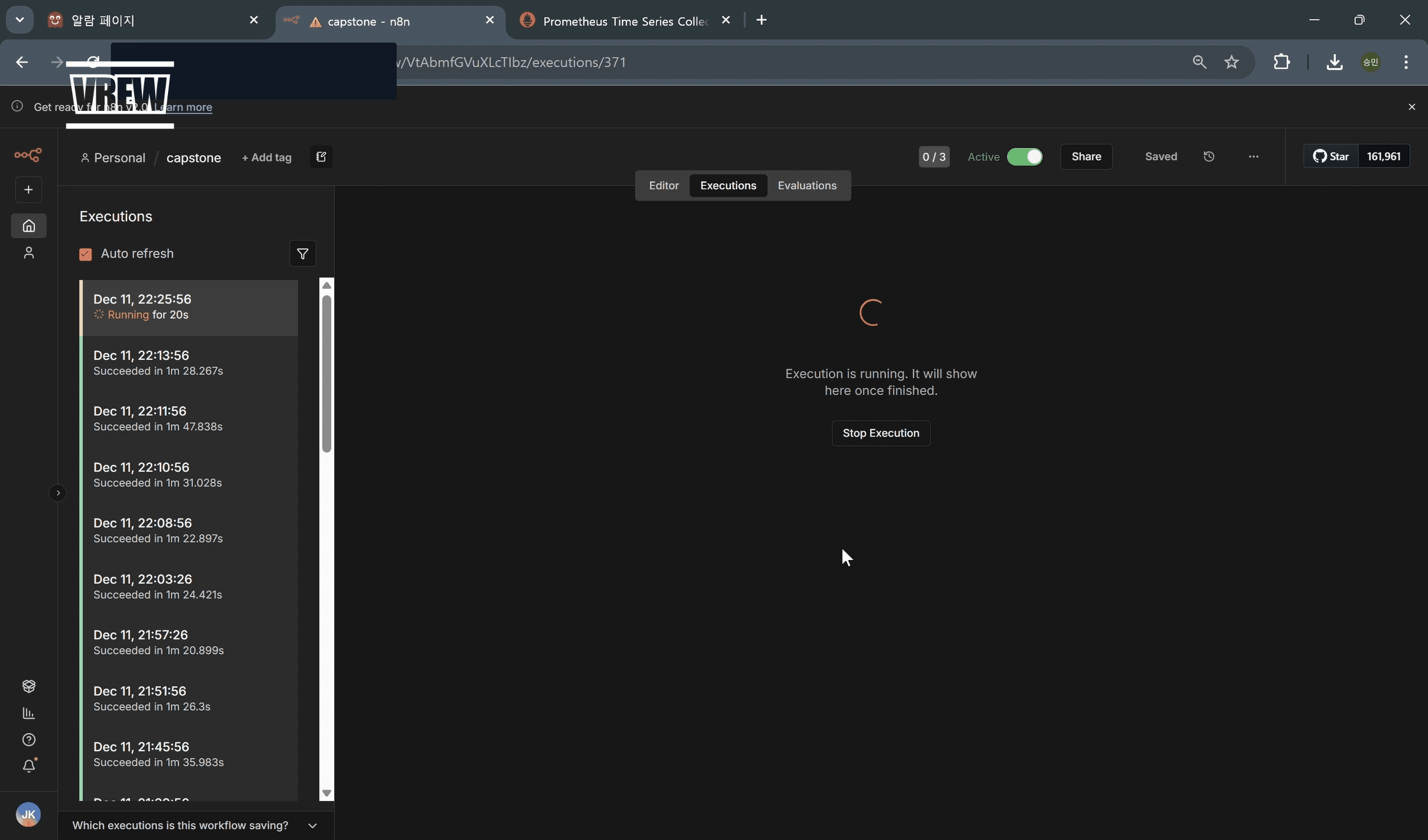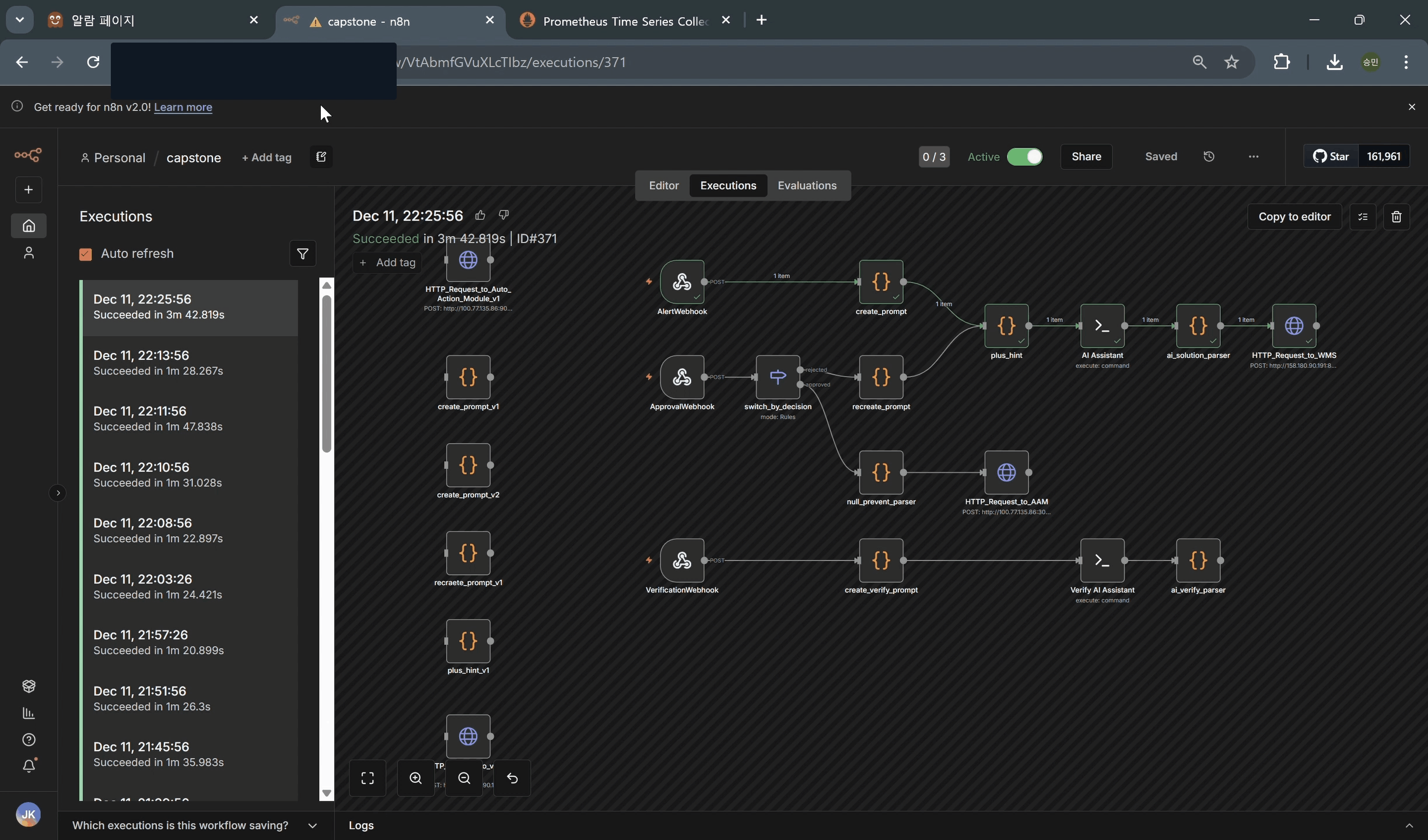
- 해결책 거절 및 새로운 해결책 확인(4_reject_solution_and_check_other_solution)

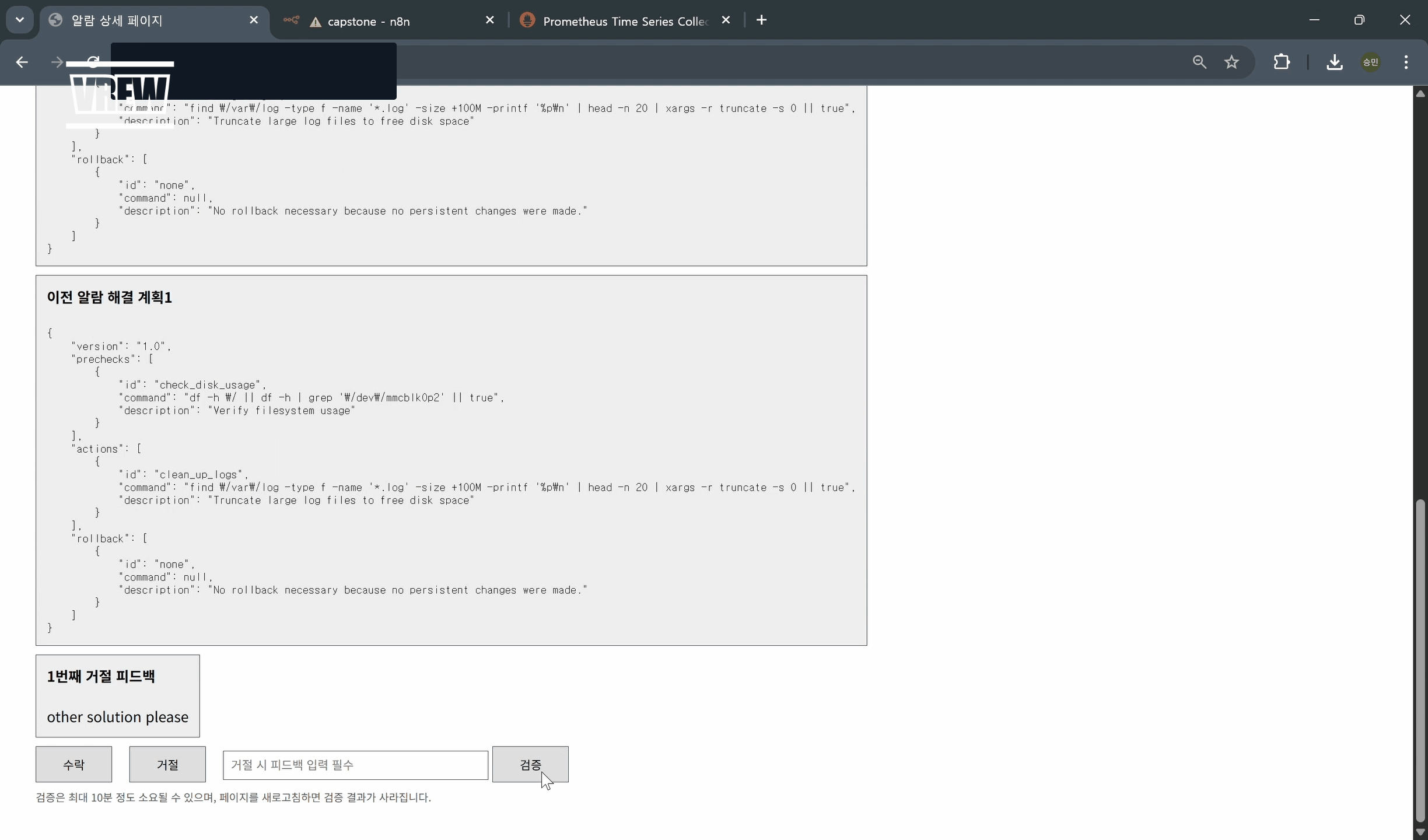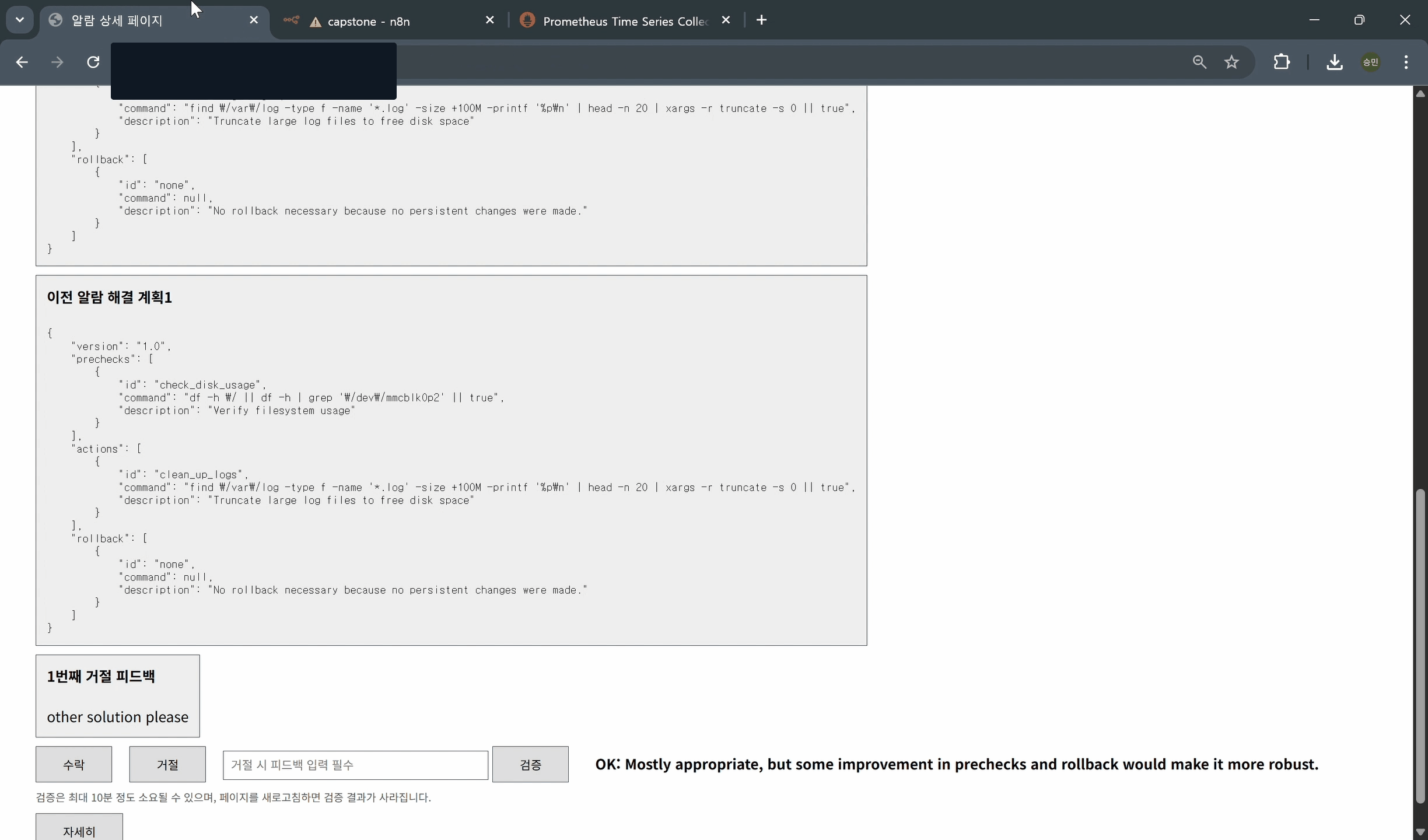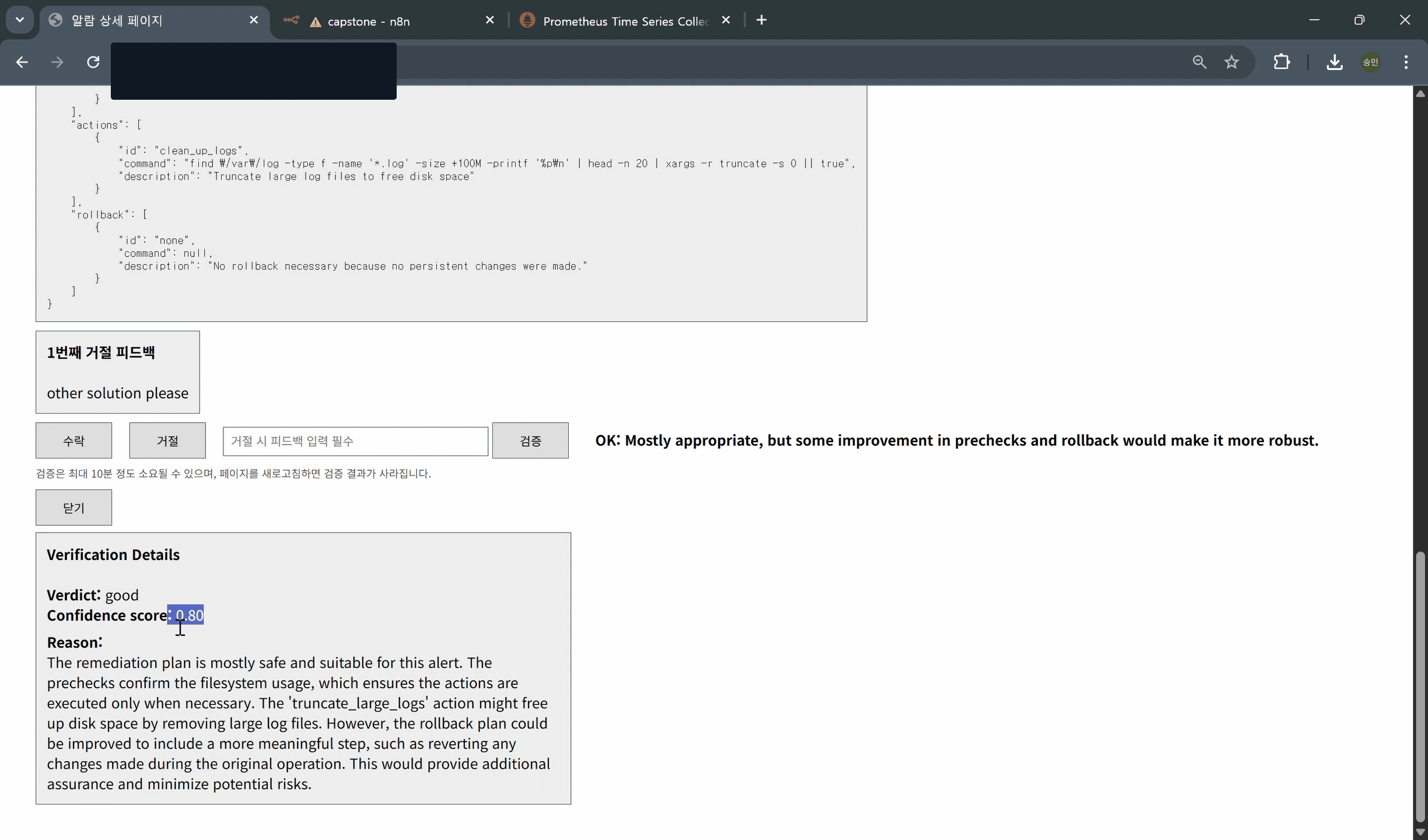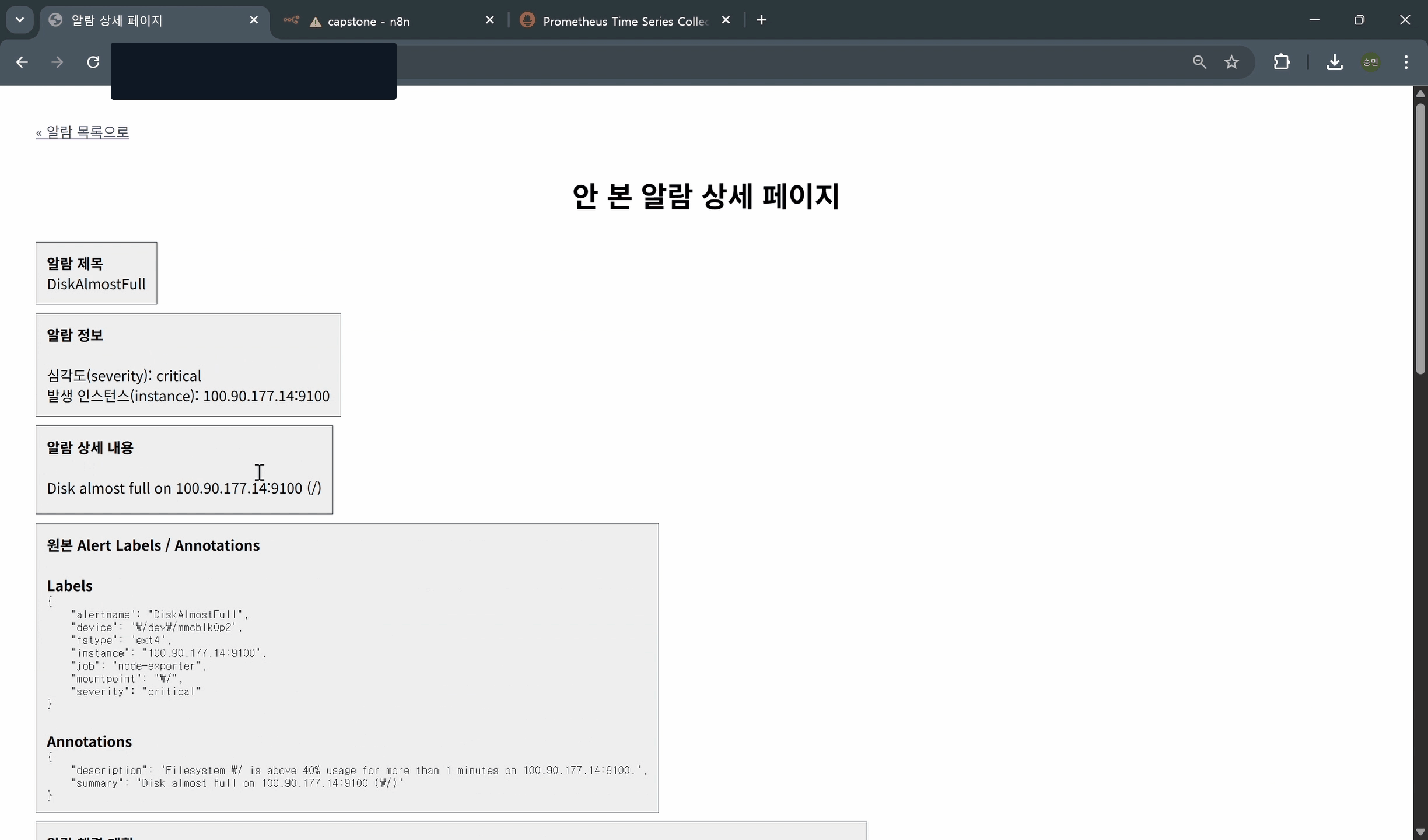
- 해결책 검증(5_verify_solution)
- 해결책 적용 및 결과 확인(6_apply_solution_and_check_result)

### 4) (Logs) 자동 조치 모듈 로그 확인
- SSH로 대상 호스트에 접속해 precheck/action 수행, 결과를 Alert API로 전달하는 흐름 확인
- check_apply_solution_in_monitor_node(해결책 적용 수행 노드):

- check_apply_solution_in_service_node(해결책 적용 대상 노드):

## Report / Evaluation
### Baseline 설정
본 프로젝트의 성능을 평가하기 위해 AI 어시스턴트를 사용하지 않는 수동/부분 자동화 운영 방식을 baseline으로 정의한다. 두 환경 모두 Prometheus/Alertmanager의 동일한 임계치 기반(alert_rule) 설정을 사용하며, 차이는 알람 이후 대응 방식에 있다.
- Prometheus/Alertmanager에서 DiskAlmostFull 임계치 기반 알람 설정
- 알람 발생 시 운영자가 Slack/이메일/웹 콘솔로 알림 수신
- 운영자가 Grafana/로그를 직접 확인하여 원인 분석
- SSH 접속 후 수동으로 명령어 실행 및 조치 수행
- 조치 결과를 엑셀/노션/위키 등에 수동 기록
제안 시스템은 동일한 알람을 n8n·WMS·AI 어시스턴트로 전달하여 remediation plan을 자동 생성하고, 운영자의 승인 후 자동 실행하는 점에서 baseline과 구분된다.
### 실험 설계
`평가는 DiskAlmostFull 장애를 대상으로 baseline과 제안 시스템을 동일 조건에서 아래의 내용에 따라 반복 실험하여 비교한다.`
| 구분 | 내용 |
|------|------|
| 실험환경 | - Prometheus + Alertmanager + Grafana + AAM
- 테스트용 서버(라즈베리파이) + n8n·WMS·AI 어시스턴트로 구성 |
| 시나리오 | - 공통: 디스크 사용량을 임계치 이상까지 증가시켜 DiskAlmostFull 알람 유발
- Baseline: 운영자가 직접 분석·SSH 조치
- 제안 시스템: AI가 생성한 plan을 WMS에서 승인 후 자동 실행 |
| 평가지표 | - 장애 감지 정확도: 의도적으로 유발한 장애 중 알람이 정상 발생한 비율
- 대응 지연 시간: 알람 발생 시각 ~ 첫 조치 실행 시각까지 시간
- 자동화 성공률: 자동 실행되는 모든 워크플로우가 완전히 실행된 비율
- 해결 성공률(해결책 정확도): 단일 조치로 장애가 완전히 해소된 비율 |
### 실험 결과
`아래는 4가지 지표에 대한 실험결과이다. baseline과 제안 시스템 환경에서 각 10번씩 실험을 진행하였다.`
| 평가 지표 | Baseline | 제안 시스템 | 목표치 |
|----------|----------|-------------|--------|
| 장애 감지 정확도 | 100% | 100% | ≥ 90% |
| 평균 대응 지연 시간 | 9.2분 | 5.3분 | ≤ 5min (43% 감소) |
| 자동화 성공률 | 0%
(자동화 미사용) | 100% | ≥ 80% |
| 해결 성공률
(1차 조치로 완전 해결된 비율) | 60%
(수동 1차 조치) | 80%
(AI plan 1회) | ≥ 80% |
`이를 통해 제안 시스템이 baseline에 비해 대응 시간 단축, 자동화 수준 향상, 해결 성공률 개선에 기여함을 확인할 수 있다.`